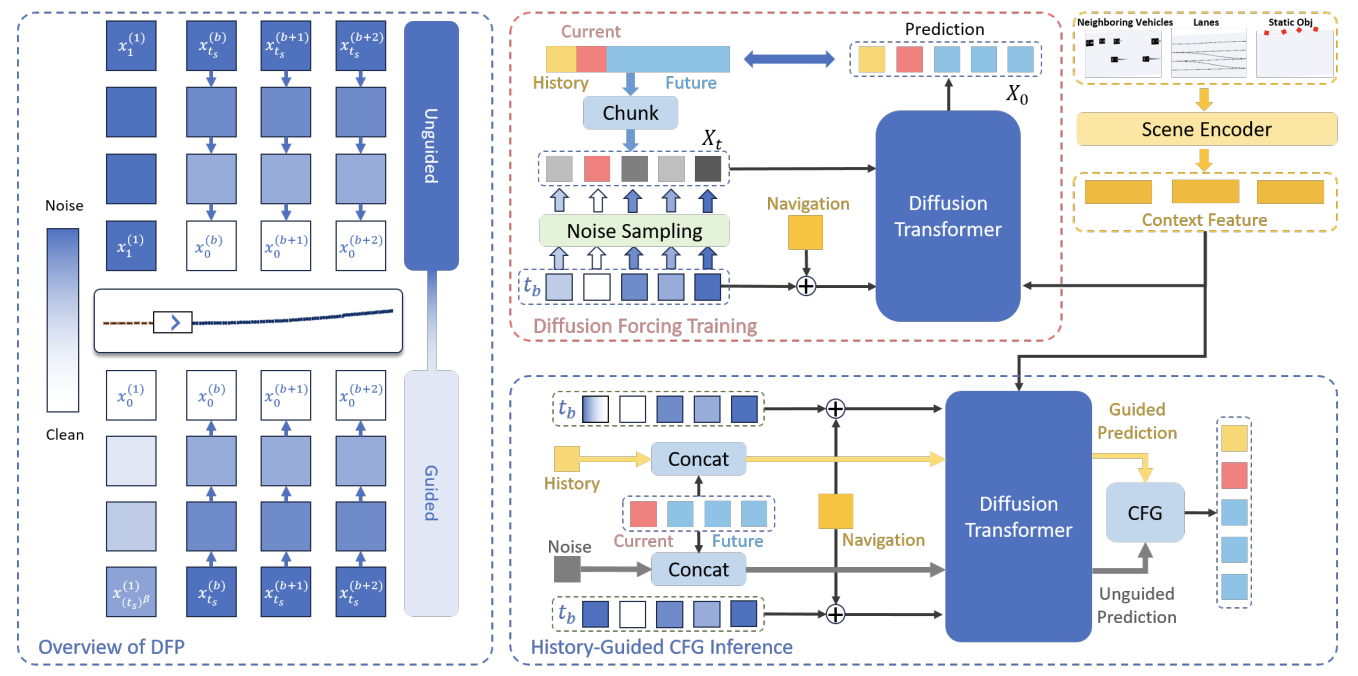
Diffusion Forcing Planner:历史退火,可控规划
一句话精髓: 历史轨迹不是负担,而是一根可调节力度的"稳定器"——DFP 用扩散过程中的噪声退火机制,让自动驾驶规划既能记住过去、又能随机应变,在平稳舒适与灵活响应之间达成平衡。
想象一个老司机:他既要参考过去几秒的驾驶感受来保持平稳,又不能被历史习惯"带偏"、错过眼前突发的路况变化。DFP 要解决的,正是自动驾驶中如何优雅地、可控地利用历史轨迹这一难题。
1. 引言:轨迹"抖动"是个老大难
1.1 问题根源
扩散模型(Diffusion Model)因其强大的多模态分布表达能力,近年来成为自动驾驶规划的明星。但它有一个顽固的毛病:哪怕场景只发生了微小扰动,模型输出的轨迹就可能大幅漂移——前一帧还好好的,下一帧突然抖了一下,驾乘体验极差,更别提安全性。
1.2 历史信息:用还是不用?
直觉上,把历史轨迹作为条件输入应该能稳定输出。但现有方法面临两难:
- 把历史当静态条件:模型学会了"抄历史",路况变化时反应迟钝(因果混乱问题)
- 直接丢弃历史:帧间一致性消失,轨迹依然抖
1.3 DFP 的核心思路
历史要用,但要可控地用——像一个旋钮,而不是一个开关。
灵感来自视频生成领域的 Diffusion Forcing Transformer(DFoT),用"加噪=遮掩"(noising-as-masking)机制让历史信号强度可调。
1.4 三大贡献
- 扩散强迫规划范式:按块(Chunk)联合训练历史和未来,随机化每块的噪声级别,强迫模型学习因果一致的生成
- 历史退火 CFG 推理:两分枝并行推理,融合输出,在"稳定"与"响应"之间可调节平衡
- 强悍的实验结果:nuPlan 闭环基准上超越所有主流方法,无需后处理
2. 相关工作:前人踩过的坑
2.1 模仿学习与"因果混乱"
ChauffeurNet、PlanTF、PLUTO 等端到端方法大量使用模仿学习。一旦把自车历史轨迹作为条件,模型就容易产生因果混乱——它学会了"复制历史运动模式",而非真正理解"为什么要这么开",分布外场景下性能崩塌。
部分方法选择直接丢弃历史(如 DiffusionDrive)以避免偏差,但代价是牺牲时间一致性。DFP 认为:历史不该被丢弃,而应通过扩散引导动态调节。
2.2 扩散模型作为轨迹生成器
Diffuser、Diffusion Policy 奠定基础,Diffusion Planner 等将其引入自动驾驶。但这些方法完全不用自车历史,也没有推理时控制历史影响强度的机制。DFP 的直接前身正是 Diffusion Planner。
2.3 时间一致性的结构化方法
Action Chunking、Streaming Flow Policy、Past Token Prediction、Bidirectional Decoding 等方法,都把时间一致性当成生成后的修补层,而非内嵌于生成过程本身。DFP 的核心创新正是把历史引导融入扩散去噪过程内部。
3. 方法:DFP 的两大核心机制
3.1 问题形式化
给定场景上下文 C(周围车辆、静态障碍物、车道信息、导航路线)和历史信息 H,生成未来规划轨迹 x₁。每个轨迹点由四元组表示:
(x, y, cosθ, sinθ) ← 位置 + 朝向
3.2 轨迹分块:N=6 个 Chunk
完整轨迹(过去 2 秒 + 当前 + 未来 8 秒,10Hz 采样)被均匀切分为 N=6 个块,每块 L=20 个轨迹点:
[历史块×1] [当前块×1] [未来块×4]
NH=1 1 NF=4
←20点→ ←20点→ ←各20点→
说明:当前块只有单个时刻,通过复制到 20 个点来凑满块长,以统一处理。 NH=1、NF=4 是根据数据规格(2s 历史 + 8s 未来)推算的,论文正文没有明确写出具体数值。
为什么要分块? 若每个时刻点单独分配一个噪声级别(块长 L=1),每个 token 缺乏轨迹语义,模型需要从海量噪声微步中拼凑连贯计划,反而更难学。块长 L>1 后,每个 token 携带丰富的轨迹片段语义,训练更稳定(消融实验 A2 vs A3 验证了这一点)。
3.3 模型输入张量
输入形状为 B × S × (4L),三个维度含义如下:
| 维度 | 含义 | 具体值 |
|---|---|---|
| B | Batch size,批大小 | 训练时 2048 |
| S | Token 数量(即块数) | 6 |
| 4L | 每个块展平后的特征维度 | 4×20=80 |
S 维度就是 token 维度——每个块对应一个 token,类比 NLP 中每个词对应一个 token,只不过这里每个 token 是一段 20 点的轨迹片段。
关于块内 20 个点的时序:论文没有明确说明块内点的顺序如何编码,推测是展平后隐含在特征排列中,由线性投影层自己去学。
3.4 训练:扩散强迫(Diffusion Forcing)
核心操作:给每个块独立分配噪声级别,强迫模型学习因果一致的生成。
当前块: 噪声级别固定为 0(t_cur = 0)← 硬边界,精确锚定当前状态
历史块: 噪声级别从 Beta 分布随机采样
未来块: 噪声级别从 Beta 分布随机采样
噪声注入方式(SDE marginal):
x_(b)_t = α(t) × x_(b)_0 + σ(t) × ε, ε ~ N(0,1)
训练损失对历史块和未来块的重建误差分别加权:
L = λ_hist × (历史块预测误差) + λ_futr × (未来块预测误差)
为什么要预测历史?这里有一个关键的理解:
训练时历史块被随机加噪,当噪声很大时历史几乎不可见,模型必须从场景上下文 C 和轨迹结构中反推"历史应该长什么样"。这并非真正要让模型预言过去,而是一种训练手段:
- 防止模型学成"复制粘贴历史"的捷径
- 迫使模型理解历史→当前→未来的真正因果关系
- 为推理时的双分枝 CFG 铺垫(让模型见过历史完全不可见的情形)
就像训练厨师:有时给完整食谱,有时遮住前几步,要求两种情况下都能做出合理的菜——他就不是在背食谱,而是真正理解了烹饪逻辑。
模型输出包含对历史块的预测,但推理时这部分直接被丢弃——历史块的预测在推理阶段没有意义,但它在训练中强迫了模型建立正确的因果表示。这就好比草稿纸上的推导过程,最终被丢掉,但正因为写了草稿,最终答案才是对的。
历史块噪声采样的分布:使用 Beta 分布,使样本更集中于两个极端(t≈0 干净 和 t≈1 纯噪声)。这让模型在训练时充分见到"历史完全清晰"和"历史完全遮掩"两种极端情形,与推理时双分枝的设计配套。
3.5 推理:历史退火 CFG(History-Annealed CFG Inference)
推理时同时跑两条并行分枝,共享同一个去噪采样器:
无引导分枝(Unguided Branch)
历史块全部替换为纯噪声,历史块时间设为 1(最大噪声):
X̂₀_unguided = f_θ([ε, X_ts], t, C)
其中历史块时间 t = {1,...,1, 0, ts,...,ts}
相当于"完全不看过去,只看当前和场景"。
有引导分枝(Guided Branch)
将真实历史 X_history 退火加噪后作为条件:
X_guidance = α(t_hist) × X_history + σ(t_hist) × ε
其中 t_hist = (ts)^β,β ≥ 1
关于"退火"的含义
“退火"借自冶金学——钢铁加热后慢慢冷却,内部结构趋于稳定有序。在这里指历史信号的噪声程度随推理进程变化:
扩散步进度: 开始(ts=1) ─────────────────→ 结束(ts=0)
ts 本身: 1.0 0.8 0.6 0.4 0.2 0.0
(ts)^β(β=2): 1.0 0.64 0.36 0.16 0.04 0.0
历史清晰度: 模糊 ──────────────────────→ 清晰
(ts)^β 比 ts 本身下降得更快(β≥1 时),所以历史在推理早期就已经相对清晰,而不是拖到最后才清晰。这样历史引导能在未来轨迹去噪的初期就发挥作用,帮助未来轨迹从一开始就朝着一致的方向收敛。
重要澄清:X_history 自始至终都是真实的历史轨迹,只不过被混入了不同程度的噪声再喂给模型。随着推理进行,噪声越来越少,真实历史的"能见度"越来越高。历史块不是被模型去噪的对象,而是作为条件信号存在。
CFG 融合
X̂₀ = X̂₀_unguided + w × (X̂₀_guided − X̂₀_unguided)
w ∈ [0,1] 是可调节的历史引导强度:w=0 完全不看历史,w=1 全听历史。最优超参为 w=0.2,β=2.0。
最终未来轨迹通过相邻块之间的线性羽化(linear feathering)平滑拼接,确保衔接处不突变。
一个完整的直觉类比:
想象你开车,副驾驶是你的"历史记忆”:
- 推理刚开始:副驾驶戴着厚厚的墨镜,你主要靠眼前路况开车
- 推理进行中:墨镜慢慢摘下,你开始参考过去几秒的驾驶感觉
- 推理结束:副驾驶完全清醒,最终轨迹在兼顾路况的同时平滑延续历史驾驶状态
3.6 模型架构:DiT-based 扩散 Transformer
骨干是 Diffusion Transformer(DiT),沿用 Diffusion Planner 的场景编码器。
Token 级位置嵌入
每个块(token)有独立的可学习位置嵌入,编码其在序列中的位置:
x̃ = MLP(x) + x_embedding
Per-token 时间嵌入
每个 token 有自己的扩散时间 t(该块当前的噪声级别),经正弦 Fourier 特征 + 小型 MLP 映射为 D 维嵌入。导航路线 R 广播到每个 token 后与时间嵌入相加,形成条件向量:
y = t_embedding + R
DiT Block
每个 Block 包含三步:
① x̃ = x̃ + MHSA(adaLN(x̃, y)) ← 自注意力:跨历史/当前/未来 token
② x̃ = x̃ + MHCA(adaLN(x̃, y), C) ← 交叉注意力:注入场景上下文
③ adaLN 调制的 MLP 输出层
adaLN 注入的条件信息
adaLN(adaptive LayerNorm)的工作方式是用条件向量动态预测缩放和偏移参数:
adaLN(x, y) = γ(y) × LayerNorm(x) + δ(y)
注入的条件信息 y = 扩散时间嵌入 + 导航路线 R。
为什么导航路线 R 不并入场景上下文 C,通过交叉注意力注入,而是用 adaLN?
R 和 C 在性质上有本质区别:
| 导航路线 R | 场景上下文 C | |
|---|---|---|
| 内容 | 车要去哪里 | 周围有什么 |
| 性质 | 全局意图,影响整条轨迹 | 局部感知,影响具体决策 |
| 与 token 的关系 | 对所有 token 一视同仁(广播) | 不同 token 需关注不同局部元素 |
adaLN 用统一的方式调制所有 token 的归一化参数,适合"全局、均质"的条件(R);交叉注意力允许每个 token 选择性地关注条件序列的不同位置,适合"局部、异质"的条件(C)。
注意:这一设计是直接沿用自 Diffusion Planner,论文为了对比公平没有改动,也没有做消融实验专门验证这个选择的必要性。
4. 实验
4.1 实验设置
测试平台:nuPlan —— 超过 1200 小时专家驾驶数据,涵盖多种路况、交通密度和多智能体交互,是目前最权威的自动驾驶规划闭环基准。
三个测试分集:
- Val14:1118 个验证场景(调参 + 消融)
- Test14-random:200+ 个随机场景(无偏性能估计)
- Test14-hard:272 个困难场景(PDM 规则基线的最差情形,专考安全关键交互)
两种评估设置:
- 非反应式(NR):其他智能体按日志重放
- 反应式(R):其他智能体由 IDM 策略控制
所有方法均直接使用原始模型输出,不加任何后处理,以保证公平比较。
对比基线(由弱到强): PDM-Open → UrbanDriver → GameFormer → PlanTF → PLUTO → CoPlanner → Diffusion Planner(DFP 的直接前身)
4.2 训练细节
| 配置项 | 值 |
|---|---|
| 训练数据 | 100 万条 nuPlan 片段 |
| 片段长度 | 过去 2s + 未来 8s,10Hz |
| 坐标系 | 自车中心系(当前位置为原点,航向对齐 x 轴) |
| 块数 N | 6 |
| 块长 L | 20 |
| 批大小 | 2048 |
| 训练轮数 | 500 epochs(含 5 epoch warmup) |
| 优化器 | AdamW,lr=2e-4 |
| 历史噪声分布 | Beta 分布(集中于 0 和 1 两端) |
4.3 主要结果
| 方法 | Val14-NR | Val14-R | Test14-NR | Test14-R | Test14-hard-NR | Test14-hard-R |
|---|---|---|---|---|---|---|
| Diffusion Planner* | 87.87 | 77.48 | 90.01 | 79.61 | 74.26 | 61.25 |
| DFP(ours) | 90.33 | 79.97 | 90.69 | 81.96 | 76.91 | 63.56 |
| DFP-FM(ours) | 92.68 | 81.30 | 90.62 | 83.59 | 79.43 | 67.94 |
| Expert Log-replay | 93.53 | 80.32 | 85.96 | 68.80 | 94.03 | 75.86 |
核心提升:
- Val14:非反应式 +2.46,反应式 +2.49
- Test14:非反应式突破 80 分大关
- Test14-hard:非反应式 +2.65,略超 CoPlanner
4.4 场景级深度解析
| 场景 | PlanTF | Diffusion Planner | DFP | 提升 |
|---|---|---|---|---|
| 所有场景(1118) | 84.27 | 87.80 | 90.33 | +2.53 |
| 低速匀速(100) | 85.00 | 86.51 | 91.08 | +4.57 |
| 高速匀速(99) | 89.39 | 84.50 | 94.95 | +10.45 |
| 左转起步(100) | 80.42 | 82.38 | 86.74 | +4.36 |
| 右转起步(98) | 70.13 | 78.16 | 79.38 | +1.22 |
最引人注目的是高速匀速场景:舒适度指标从 60.61 跃升至 96.97,整整提升了 36 分。这说明 DFP 在高速稳定行驶时极为平稳,历史引导 CFG 有效抑制了轨迹抖动。
5. 消融实验:一块一块拼起来
| 变体 | 扩散强迫 | 块级Chunk | 历史引导 | 历史退火 | Val14-NR | Val14-R |
|---|---|---|---|---|---|---|
| A1(基线 DP) | ✗ | ✗ | ✗ | ✗ | 87.87 | 77.48 |
| A2(逐点噪声,L=1) | ✓ | ✗ | ✗ | ✗ | 85.18 | 75.27 |
| A3(只加块) | ✗ | ✓ | ✗ | ✗ | 87.58 | 77.10 |
| A4(块级扩散强迫) | ✓ | ✓ | ✗ | ✗ | 88.79 | 77.49 |
| A5(无块的历史引导) | ✓ | ✗ | ✓ | ✗ | 86.56 | 75.93 |
| A6(有块+干净历史引导) | ✓ | ✓ | ✓ | ✗ | 89.24 | 79.16 |
| A7(完整 DFP) | ✓ | ✓ | ✓ | ✓ | 90.33 | 79.97 |
关键结论:
- A2 反而下降:L=1 时每个 token 缺乏轨迹语义,模型需从海量噪声微步中拼凑连贯计划,反而更难
- A6 vs A7:若历史引导始终保持干净(无退火),模型会"死守"历史,对路况变化反应迟钝;退火机制让模型在历史稳定性与场景响应性之间动态平衡
超参数敏感性:
- w(历史引导强度):太小=无历史,太大=被历史绑架,最优 w=0.2
- β(退火速度):最优 β=2.0
6. 附录补充实验
6.1 Flow Matching + Mixture-of-Transformer(DFP-FM†)
将扩散采样器换成 Flow Matching,骨干升级为 Mixture-of-Transformer(MoT)(多专家 Transformer,专门处理多模态交通场景):
| 场景 | DFP | DFP-FM† |
|---|---|---|
| 所有场景 | 90.33 | 92.68 |
| 高速匀速 | 94.95 | 97.40(碰撞率降到 0!) |
| 左转起步 | 86.74 | 93.15 |
6.2 时间稳定性量化分析
通过可视化 15 秒片段的急动度(Jerk)、纵向加速度、横摆角速度,量化对比 DFP 与 DP:
- 平均 Jerk 降低 18.9%
- Jerk 标准差降低 17.0%(不仅更平均,而且更稳定)
- 横摆加速度基本持平(符合预期)
推理速度:
- 完整 CFG 推理(双分枝):~7.7 FPS(129.79ms)
- 仅无引导分枝:~14.8 FPS(67.71ms)
7. 结论与局限
总结: DFP 用两个优雅的机制解决了一个长期困扰自动驾驶规划的问题——训练时,块级扩散强迫让模型学会因果一致的生成;推理时,历史退火 CFG 让历史引导可控可调,在"平稳"和"响应"之间找到最佳平衡。
局限:
- 性能对 w 和 β 超参数较为敏感,不同场景可能需要调整
- 当前推理速度(7.7 FPS)距实时部署仍有差距
未来方向:
- 将自适应引导调度应用于端到端自动驾驶框架
- 在更广泛的基准上测试泛化能力
与相关论文的联系
- Diffusion Planner:DFP 的直接前身,核心骨干沿用,DFP 在其基础上加入了历史引导机制
- DiffusionDrive:选择直接丢弃历史来避免因果混乱,DFP 认为历史不该丢弃而应可控利用 → DiffusionDrive
- Plan-R1:同样关注自动驾驶规划的时间一致性与安全约束 → Plan-R1
- HorizonDrive:同样利用自回归结构保证时间一致性,但通过不同的机制(SRR 恢复训练 + 延迟衰减 CFG)→ HorizonDrive