背景
- Transformer摆脱了NLP任务对于RNN、LSTM的依赖,使用了self-attention的方式对上下文进行建模,提高了训练和推理的速度。
模型结构
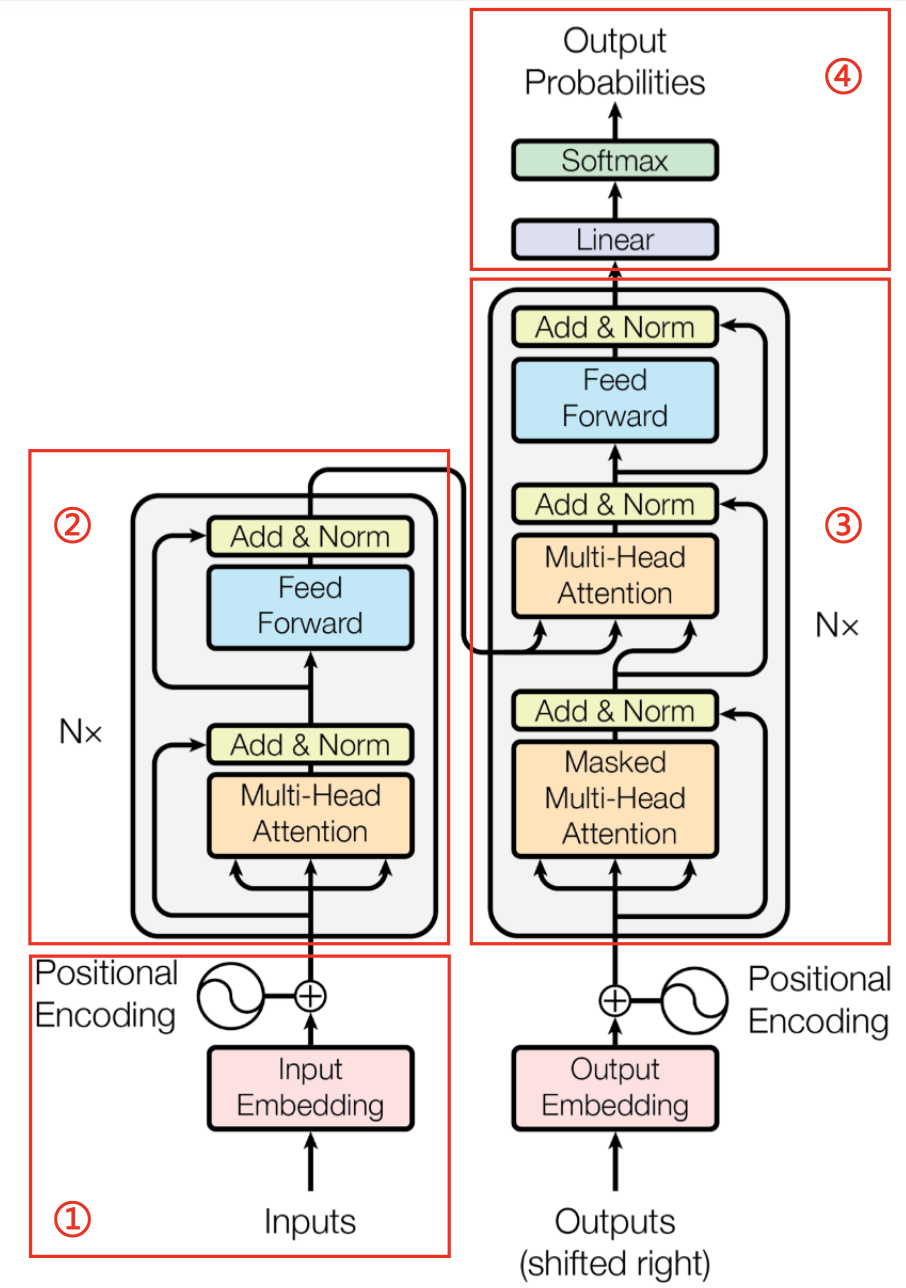
- 第一部分:输入层
- 主要包含两个主要输入,词向量与位置向量,按元素相加的方式作为模型的输入层。
- 第二部分:编码器
- N表示编码层有N个同样的编码模块,其中每个模块包含有多头注意力层(Multi-Head Attention)与前向连接层(Feed Forward),每个层之间有层归一化与残差连接层。
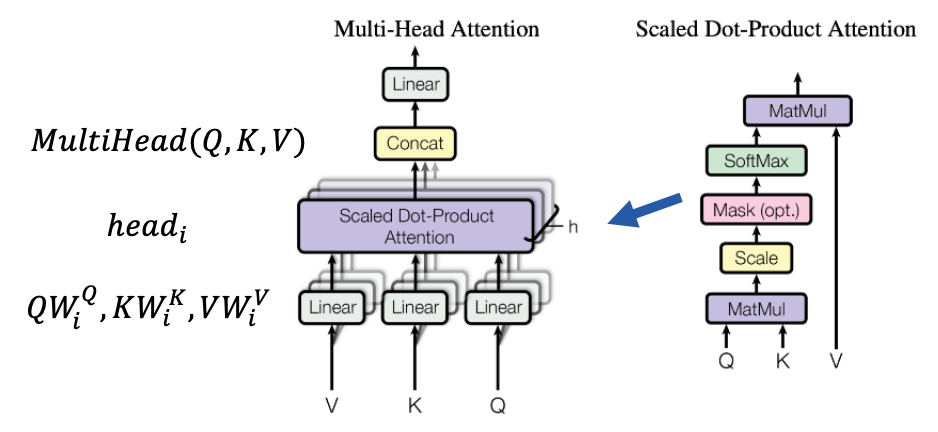
- 多头注意力层(Multi-Head Attention)
- 前向连接层(Feed Forward)
- 层归一化(Norm)

^{2}})

- 这一步的作用是前面的数据经过激活函数之后距离中心分布比较远,归一化后把这个数据分布又拉回到中心区域了,不至于越往后计算偏差越大
- 残差连接层
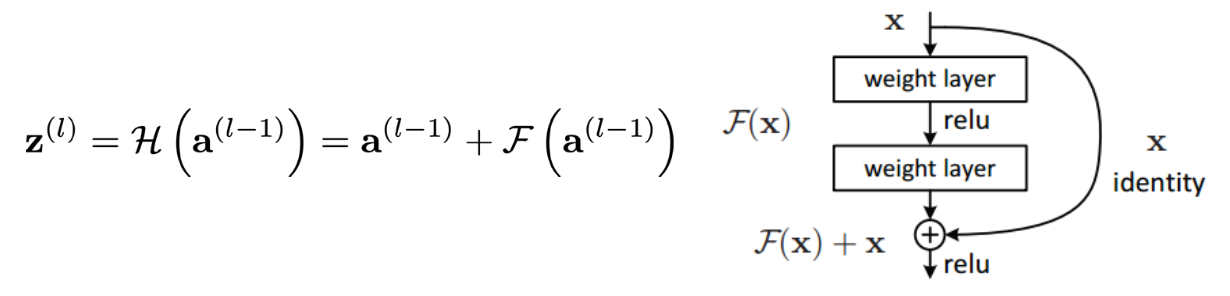
- 残差单元可以以跳层连接的形式实现,即将单元的输入直接与单元输出加在一起,然后再激活。因此残差网络可以轻松地用主流的自动微分深度学习框架实现,直接使用BP算法更新参数。
- 第三部分:解码器
- 解码层也有N个同样的编码模块,与编码层的每个模块不同的是,自注意层用的是一个Masked Multi-Head Attention层,主要是为了在解码的时候,屏蔽掉当前词后面的词(解码的时候只能获得当前单词的历史词)。
- 除此之外,自注意力层之上连接的是一个从Decoder到Encoder之间的一般注意力层(没有Masked的那个)。这里的
 来自于Encoder最后一个模块的输出层输出,而
来自于Encoder最后一个模块的输出层输出,而 则是来自Decoder自身上一层(Masked Multi-Head Attention)的输出。计算的是目标语言与源语言之间的注意力得分。
则是来自Decoder自身上一层(Masked Multi-Head Attention)的输出。计算的是目标语言与源语言之间的注意力得分。
- 第四部分:输出层
- 通过Linear层将decoder得到的向量进行变换,得到一个跟词表同样大小的向量,然后经过softmax层进行概率归一化的表示。
- 此时,得到的向量中每一个元素表示的就是预测的单词为词表中每一个单词的概率。