Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
总览
- 研究了3种场景encoder在不同位置的表现差异
- 研究了两种加速self-attention的方法:factorized attention和latent query attention
核心模块
环境编码
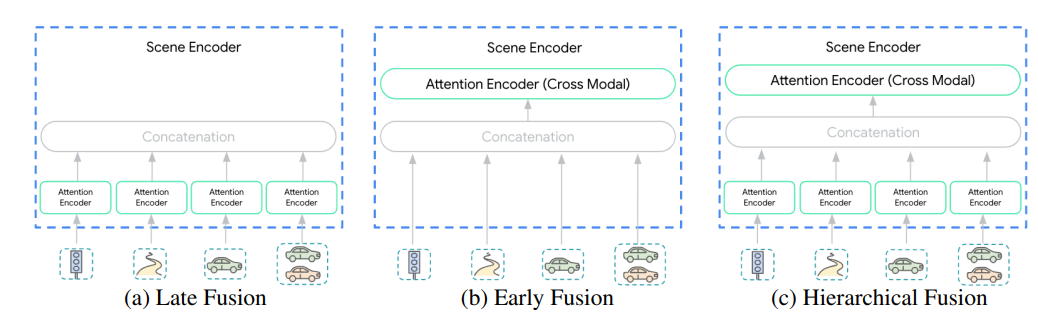
方法介绍
Late Fusion
最常用的方法,对于不同的信息,先各自做self attention。处理完后把这些feature concat起来给decoder,由decoder来做cross attention。
Early Fusion
相对早一点做fusion。还是要先经过projection,然后直接concat起来,做一个统一的self attention(实际是跨模去做attention了),每种信息给出了不同的重要程度。
Hierarchical Fusion
上面两种方式的混合。每种信息先过self attention encoder,concat起来再一起做self attention encoder。既然结构变复杂了,自然是要把模型容量控制到和上面两种做法一致才有比较的价值。需要把模型深度平分到两步attention中。
结论
- 都在multi-axis attention的情况下做实验。发现低延迟情况下,late fusion性能更好。对于小model(参数少)来说,early fusion性能更好。
注意力机制
- 环境信息编码size:\(A*T*S_{surrounding}*D\),其中 \(A\)是待预测的agent的数量,\(T\)是历史信息时长,\(S_{surrounding}\)是agent周围交互元素的数量(包括其他agent、地图、信号灯等)
- self attention的参数量级是和序列长度的平方成正比的,直接将所有信息进行self attention非常耗时。
方法介绍
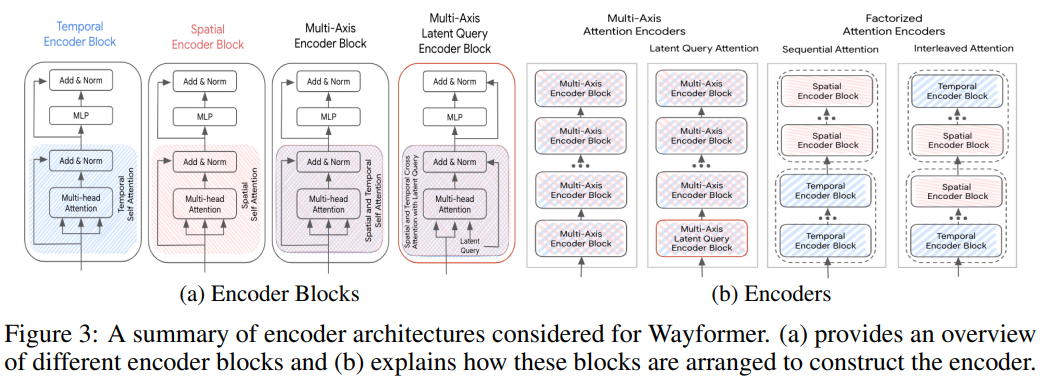
Multi-Axis Attention
- 这是baseline。做法是同时处理时空维度(\(T*S_{surrounding}\)),即把时间空间维度reshape到一起,最为耗时,所有的fusion方式的时间复杂度为\(O(T^{2}S_{surrounding}^{2})\)。
Factorized Attention
- 为了解决baseline中提到的高复杂度问题,采用了分两次计算的方法。时间维度做一次self attention,空间维度做一次self attention,这样就把复杂度里的乘法变成了加法。这样带来的麻烦是要决定一下时间和空间self attention的顺序(这也不是运算复杂度,所以无所谓)。这里比较了两种方法:Sequential attention(N个layer里面前N/2是时间attention,后N/2是空间attention),Interleaved attention(N个layer,其中时间和空间attention交替使用N/2次)。
Latent Query Attention
- 和第一种方法有点像,但是在第一个encoder block的\(Q\)项使用latent query。这个latent query把ST的维度降下来。\(KV\)的话保持了原来的\(ST\)维度,对\(Q\)而言把\(ST\)降到一个更小的维度\(L_{out}\),也就是说总的运算复杂度降低为原来的\(L_{out}/ST\)
结论
Factorized Attention:sequential attention和interleaved attention的结果基本一样。在early和late fusion情况下,factorized attention是有帮助的。在late fusion情况下对于latency的降低有很大帮助,这是因为late fusion可以在维度tile之前做attention,attention的token数量能减少很多。
Latent Queries:采用不同的降维系数,可以把模型的速度提升2到16倍,同时没有性能下降。early和hierarchical fusion的性能更好,表示了cross modal interaction的重要性。