GameFormer: Game-theoretic Modeling and Learning of Transformer-based Interactive Prediction and Planning for Autonomous Driving
问题建模
- 输入:\(N\)个agents,历史状态,地图(交通灯、车道中心线、边界线、斑马线等)
- 输出:每个agent输出 \(M\)条轨迹及对应score
- 多次迭代更新agent的预测轨迹
- 第 \(i\)个agent的第 \(k\)层策略为 \(\pi_{i}^{(k)}=min_{\pi_{i}}L_{i}^{k}(\pi_{i}^{(k)}|\pi_{\neg i}^{(k-1)})\),这边的 \(\pi \)指的是每个agent的多模态预测轨迹(GMM模型)
模块细节
Scene Encoding
- Input Representation
- agent的历史状态 \(S_{p}\in R^{N*T_{h}*d_{s}}\), \(d_{s}\)是状态属性的维度
- 局部地图polyline \(M\in R^{N*N_{m}*N_{p}*d_{p}}\),对每个agent,找到其周围的 \(N_{m}\)个地图元素,每个元素包含 \(N_{p}\)个点, \(d_{p}\)是属性维度。通过DFS为每个agent构造候选参考线,遍历候选参考线里的车道内的每个路点,记录点的位置和类型、左右边界位置和类型、限速、信号灯、信号牌等.
- Agent History Encoding
- 利用LSTM编码历史状态,得到 \(A_{p}\in R^{N*D}\),包含所有agent的过去历史信息, \(D\)是隐藏层特征维度
- Vectorized Map Encoding
- 利用MLP为所有agent编码周围地图信息 \(M_{p}\in R^{N*N_{m}*N_{p}*D}\),后面将同一个地图元素中的 \(N_{p}\)个点通过max pooling聚合,将 \(N_{p}\)维度压缩掉(类似于PointNet),新的shape为 \(M_{r}\in R^{N*N_{mr}*D}\), \(N_{mr}\)是每个agent周围的地图元素数量
- Relation Encoding
- 针对每个agent,聚合所有agent(包括它自己)的历史信息和其周围的地图信息, \(C_{i}=[A_{p},M_{p}^{i}]\in R^{(N+N_{mr})*D}\)
- 通过一个包含 \(E\)层的multi-head self-attention transformer计算彼此之间的交互,最终得到一个scene context encoding \(C_{s}\in R^{N*(N+N_{mr})*D}\)
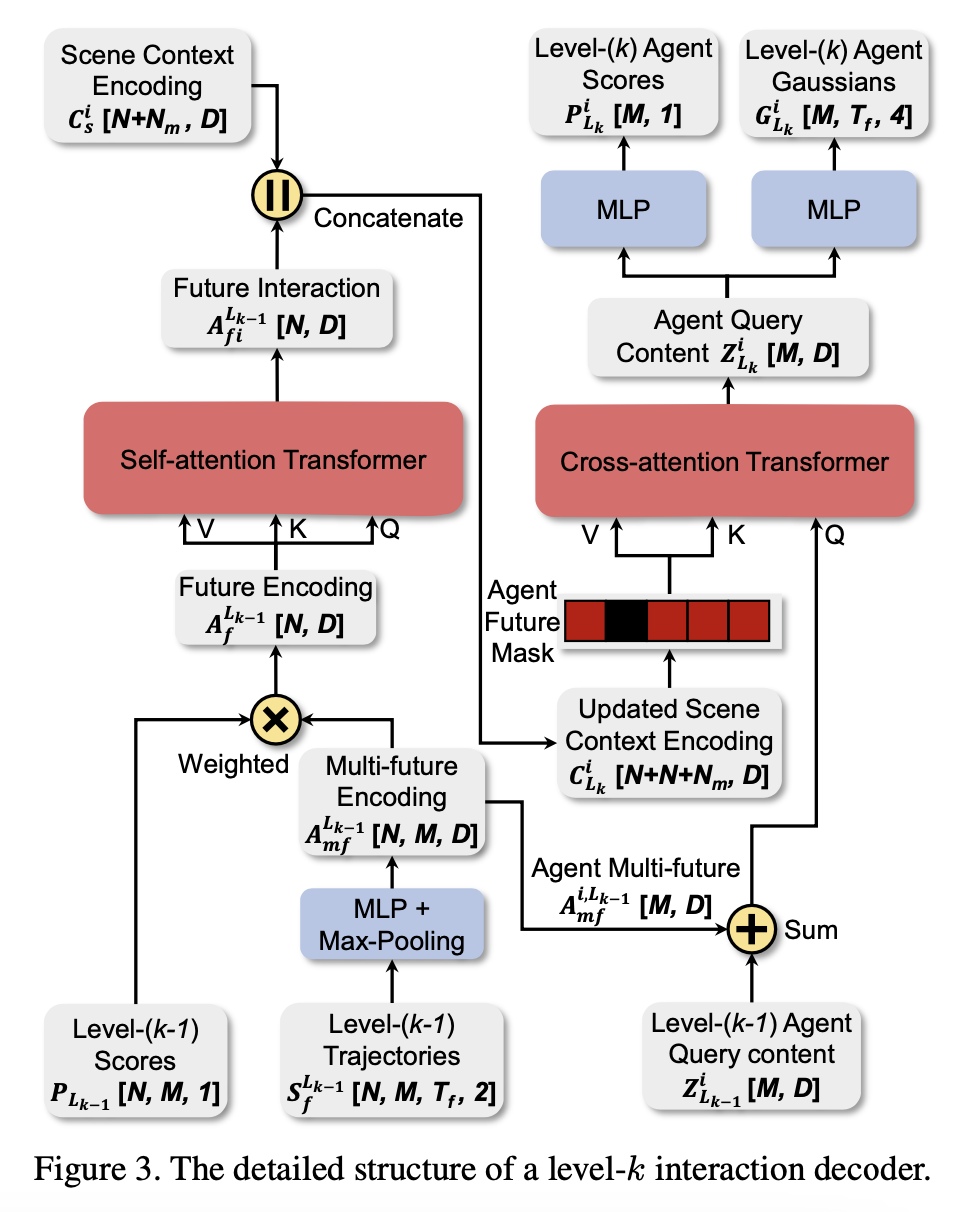
Future Decoding with Level-k Reasoning
- Modality Embedding
- 为了描述不确定信引入多模态,初始化一个可学习的modality embedding \(I \in R^{N*M*D}\), \(M\)是模态的数量
- Level-0 Decoding
- 输入 \(I\)和该agent在scene context encoding中的历史信息编码 \(C_{s,A_{p}}\)(by inflating a modality axis),得到 \((C_{s,A_{p}}+I)\in R^{N*M*D}\)作为query,然后 \(C_{s}\)作为key、value。
- multi-head cross-attention Transformer作用在每个agent的modality axis上,得到query content features \(Z_{L_{0}}\in R^{N*M*D}\)。
- \(Z_{L_{0}}\)通过一个MLP解码得到预测轨迹的GMM参数 \(G_{L_{0}}\in R^{N*M*T_{f}*4}\),4个维度对应每个timestamp的 \((\mu_{x},\mu_{y},log\sigma_{x},log\sigma_{y})\)。再通过另一个MLP解码得到每组预测的score \(P_{L_{0}}\in R^{N*M*1}\)
- Interaction Decoding
- \(k\)次迭代decode过程
- 第 \(k\)次迭代
- 取所有agent在 \(k-1\)次迭代中生成的轨迹点 \(S_{f}^{L_{k-1}}\in R^{N*M*T_{f}*2}\)(每对点是GMM参数 \(G_{L_{k-1}}\)中的 \(\mu_{x}, \mu_{y}\)),通过MLP和max pooling操作在时间维度上对轨迹进行编码,得到agent的多模预测轨迹编码 \(A_{mf}^{L_{k-1}}\in R^{N*M*D}\)
- 依据 \(k-1\)次迭代中得到的scores \(P_{L_{k-1}}\)对 \(A_{mf}^{L_{k-1}}\)在模态维度上对进行weighted-average-pooling操作,得到agent的future feature \(A_{f}^{L_{k-1}}\in R^{N*D}\)
- 通过multi-head self-attention Transformer实现 \(A_{f}^{L_{k-1}}\)之间的交互
- 针对每个agnet,将交互完成后的future feature和编码过程中得到的scene context encoding合并在一起, \(C_{L_{k}}^{i}=[A_{fi}^{L_{k-1}},C_{s}^{i}]\in R^{(N+N_{m}+N)*D}\)
- 将当前关注agent在第 \(k-1\)次迭代中得到的query content features \(Z_{L_{k-1}}^{i}\)和该agent多模预测轨迹编码 \(A_{mf}^{L_{k-1}} \)组合为query \((Z_{L_{k-1}}^{i}+A_{mf}^{i,L_{k-1}})\in R^{M*D}\),将更新过的scene context encoding \(C_{L_{k}}^{i}\)作为key和value过一遍multi-head cross-attention Transformer
- 通过mask策略阻止第 \(i\)个agent在第 \(k\)次迭代中获取到它自己在前面几次迭代中的future interaction features。只能获取周围其他障碍的future interaction features
- 最终得到的query content tensor \(Z_{L_{k}}^{i}\)通过两个MLP解码得到预测轨迹的GMM参数和每组预测的score
训练过程
Imitation Loss
- 采用imitation loss作为主要loss来规范agent的行为,以此来学习交通规则和驾驶风格等
- 通过negative log-likelihood loss,对比best prediction \(m^{*}\)(和gt最接近的预测结果)和gt来计算imitation loss
$$L_{IL}=\sum_{t=1}^{T_{f}}{L_{NLL}(\mu_{m^{*}}^{t},\sigma_{m^{*}}^{t},p_{m^{*}},s_{t})}$$
$$L_{NLL}=log\sigma_{x}+log\sigma_{y}+\frac{1}{2}((\frac{dx}{\sigma_{x}})^{2}+(\frac{dy}{\sigma_{y}})^{2})-log(p_{m^{*}})$$
- 其中, \(ds=s_{x}-\mu_{x}\), \(dy=s_{y}-\mu_{y}\), \((s_{x},s_{y})\)是gt轨迹点; \(p_{m^{*}}\)是best prediction对应的网络输出概率
Auxiliary Loss
- 充分考虑了每个agent之间的交互
- 通过一个interaction loss鼓励每个agent避免和其他agent在 \(k-1\)次迭代中生成的future traj碰撞。
- 通过一个斥力场来拉开各个agent轨迹之间的距离 $$L_{inter}=\sum_{m=1}^{M}{\sum_{t=1}^{T_{f}}{\max\limits_{\forall j\neq i,\forall n \in 1:M}\frac{1}{d(\hat s_{m,t}^{(i,k)},s_{n,t}^{(j,k-1)})+1}}}$$
- 其中 \(d(\cdot,\cdot)\)是预测轨迹点的 \(L2\)距离, \(m\)是agent \(i\)的预测轨迹模态, \(n\)是( \(k-1\)次迭代中)agent \(j\)的预测轨迹模态。
- 为了确保安全loss只在近距离被激活,引入一个安全阈值,只有距离小于安全阈值才有loss惩罚
Total Loss
$$L_{i}^{k}(\pi_{i}^{(k)})=w_{1}L_{IL}(\pi_{i}^{(k)})+w_{2}L_{inter}(\pi_{i}^{(k)},\pi_{\neg i}^{(k-1)})$$
实验
环境
- 数据集
- Waymo open motion dataset(WOMD)
- nuPlan dataset
- 实验模型
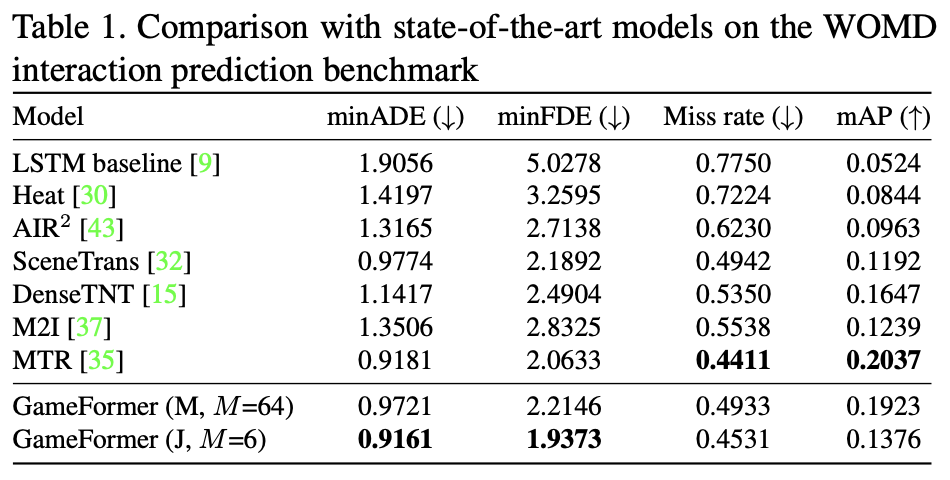
- 预测模型
- 采用WOMD训练
- 每次只评价两个被标记的交互障碍物的未来8s轨迹和真值的差距
- 评价指标包括:最小平均位移误差minADE、最小最终位移误差minFDE、未命中率 miss rate、平均精度mAP
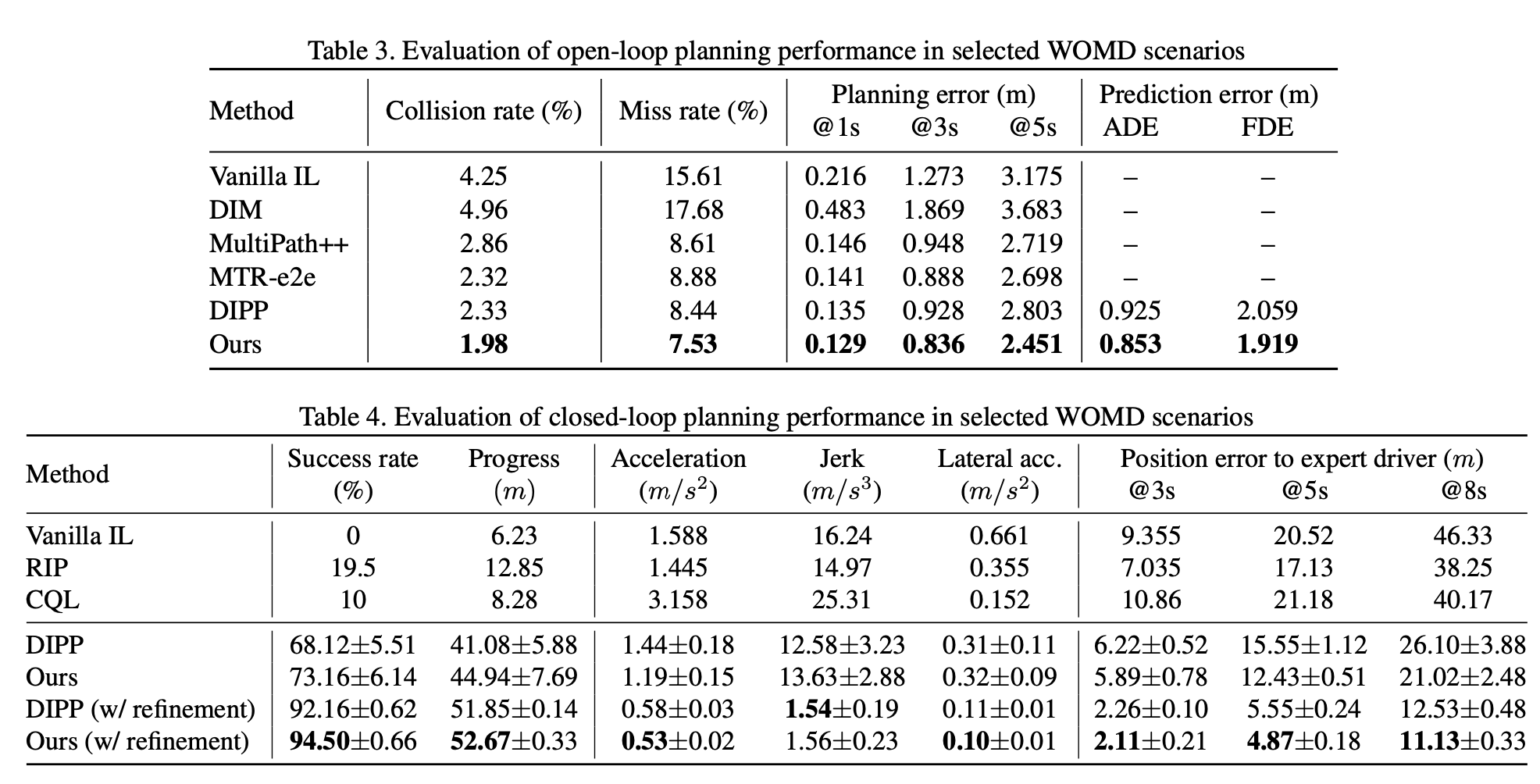
- 规划模型
-
采用WOMD和nuPlan训练
-
开环
- planning ADE、collision rate、miss rate、prediction ADE
-
闭环
- 成功率(无碰撞且无偏航)、导航完成进度、纵向acc & jerk、横向acc、位置误差
-
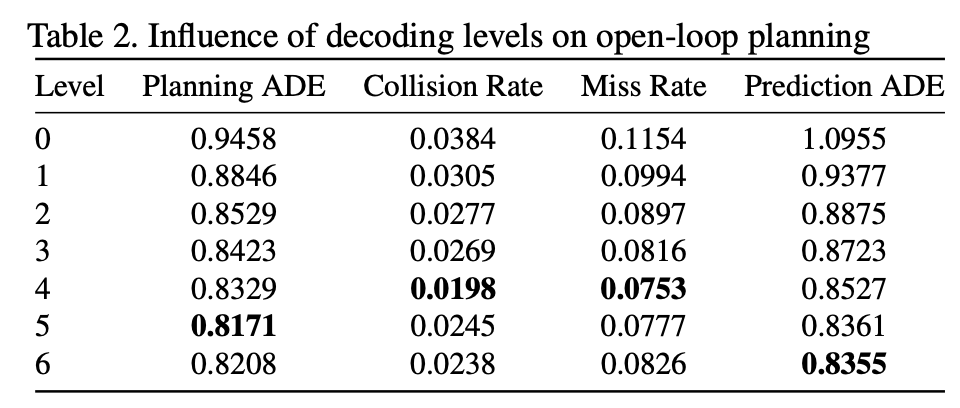
迭代层数 \(k=4\)效果最好
-
- 预测模型
- 消融实验
- agent future modeling的作用
- 第 \(k-1\)层得到的future trajectory不输入第 \(k\)层的解码过程
- 输入上一层的future trajectory,但不进行self-attention操作
- 训练过程中不引入interaction loss(Auxiliary Loss)
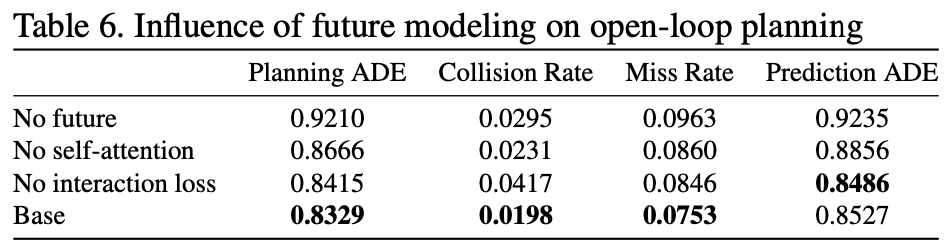
- 解码器结构的作用
- 用 \(k\)个共享权重的decoder代替当前设计中 \(k\)个独立的decoder
- 用一个multi-layer transformer代替当前设计中 \(k\)个独立的decoder
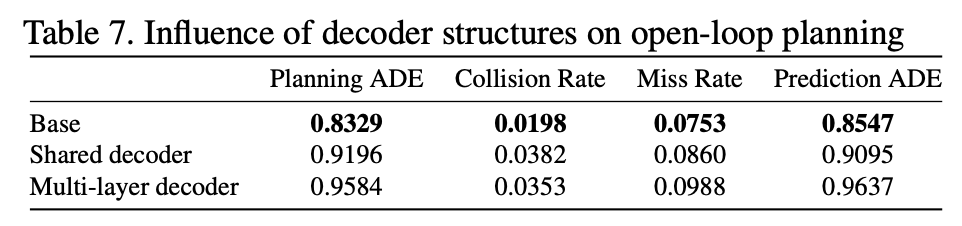
- agent future modeling的作用
代码解读
文件结构
- open_loop_planning
- data_process.py:以帧为单位打包ego, neighbors, lanes, crosswalk, ref_line数据
- open_loop_test.py:开环方式跑测试集统计相关指标
- train.py:规划模型训练
- interaction_prediction
- data_process.py:同上
- train.py:预测模型训练
- model
- GameFormer.py:GF网络主体结构
- modules.py:子网络的实现
- utils
- inter_pred_utils.py:loss定义、metrics定义
- data_utils.py:地图存储、搜错,data normalization
- cubic_spline_planner.py:Spline类定义
- open_loop_test_utils.py:open_loop_test.py中工具函数的实现
- open_loop_test_train.py:open_loop_planning/train.py中工具函数的实现
核心代码
- GameFormer.py
- GF网络主体,encoder + decoder
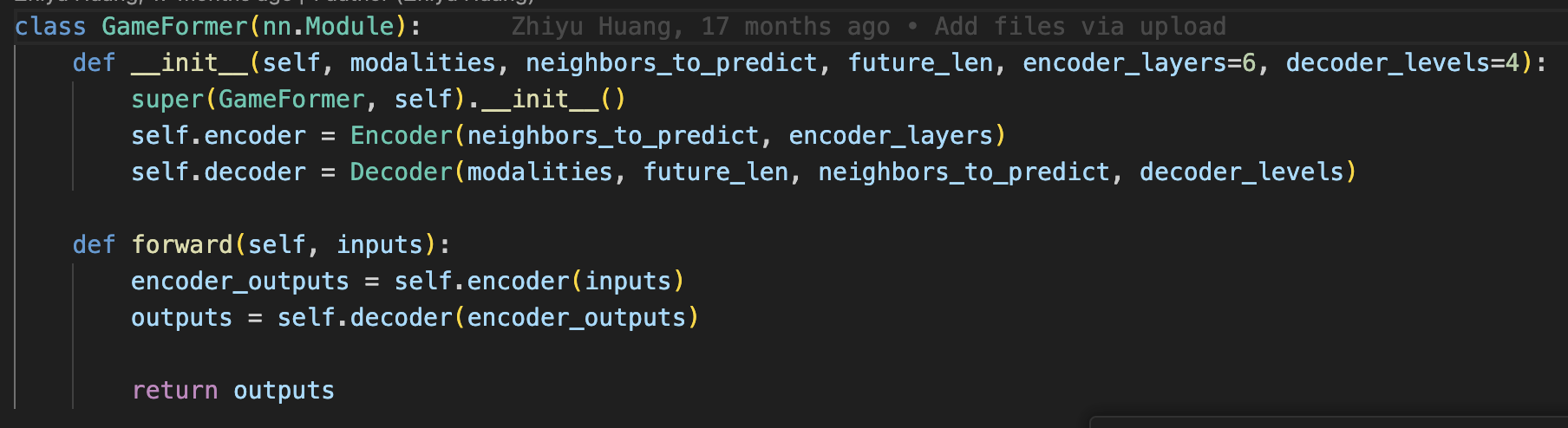
- GM.encoder
-
agent encoding( \(B*N*D\))
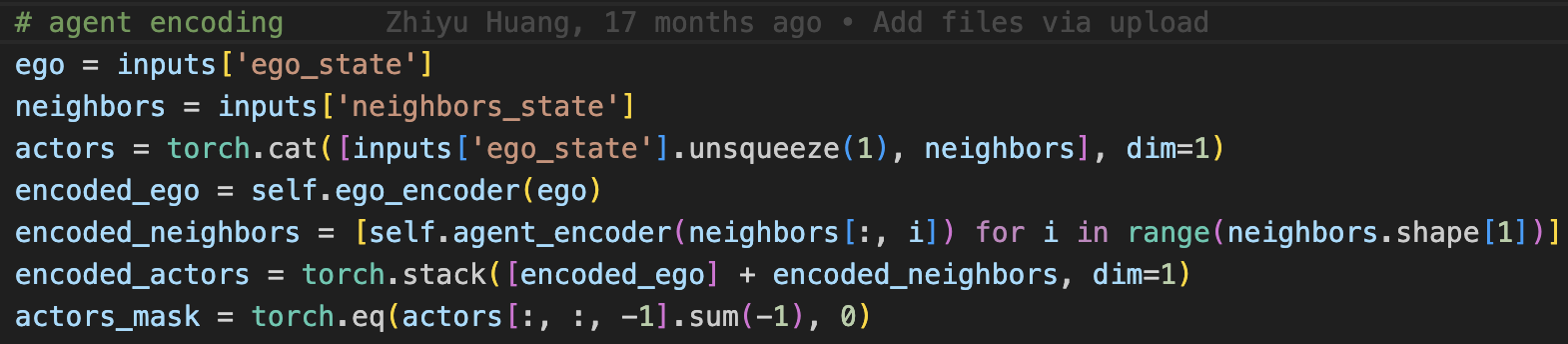
- 这里的ego encoder和agent encoder都是AgentEncoder类,concat(LSTM(state), MLP(type))
-
map encoding( \(B*N_{mr}*N_{pts}*D\))

- LaneEncoder: PE(concat(MLP(pts), MLP(spd_limit), embeding(type))),PE用的三角函数式绝对位置编码
- CrosswalkEncoder: MLP(pts)
-
fusion encoding( \(N*(N+N_{mr})*D\))
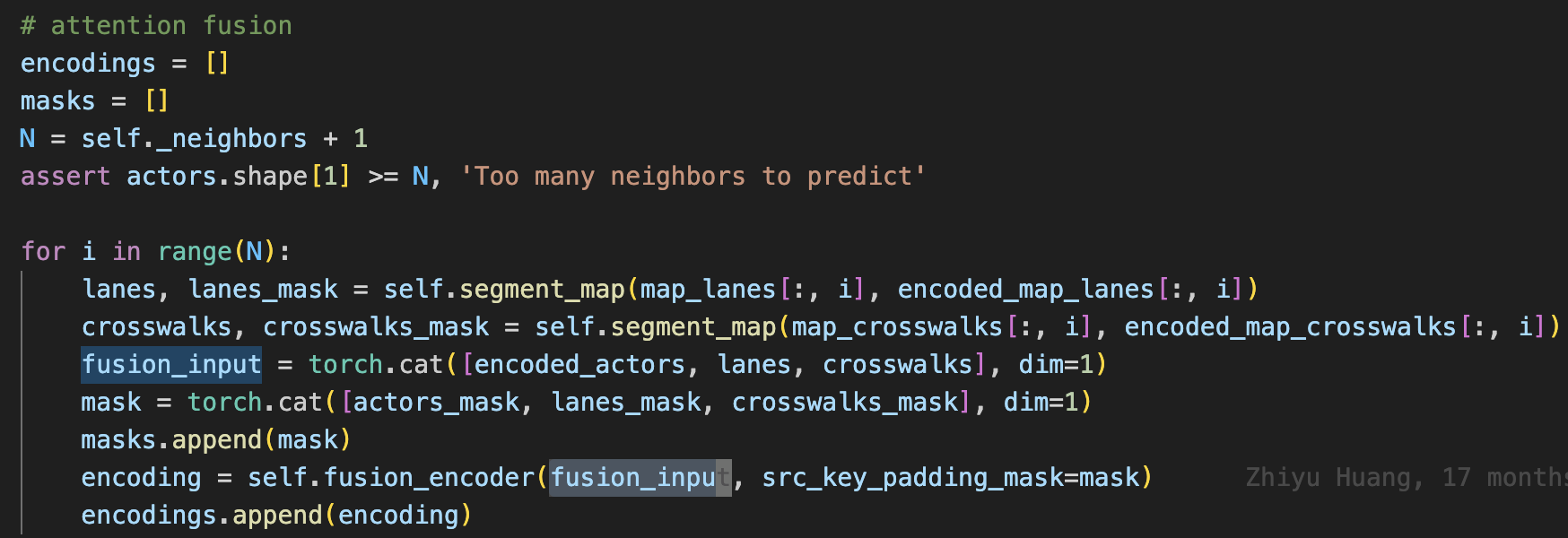
- segment_map核心是max pooling,将 \(N_{pts}\)维度压缩掉
- fusion_encoder是一个6层的transformer_encoder,计算每个agent和周围其他agent以及地图元素的关系,得到每个agent的周围环境的编码scene_context_encoding(循环 \(N\)次后stack)。
-
- GM.decoder
-
level 0 encoding

-
核心是initial_stage函数
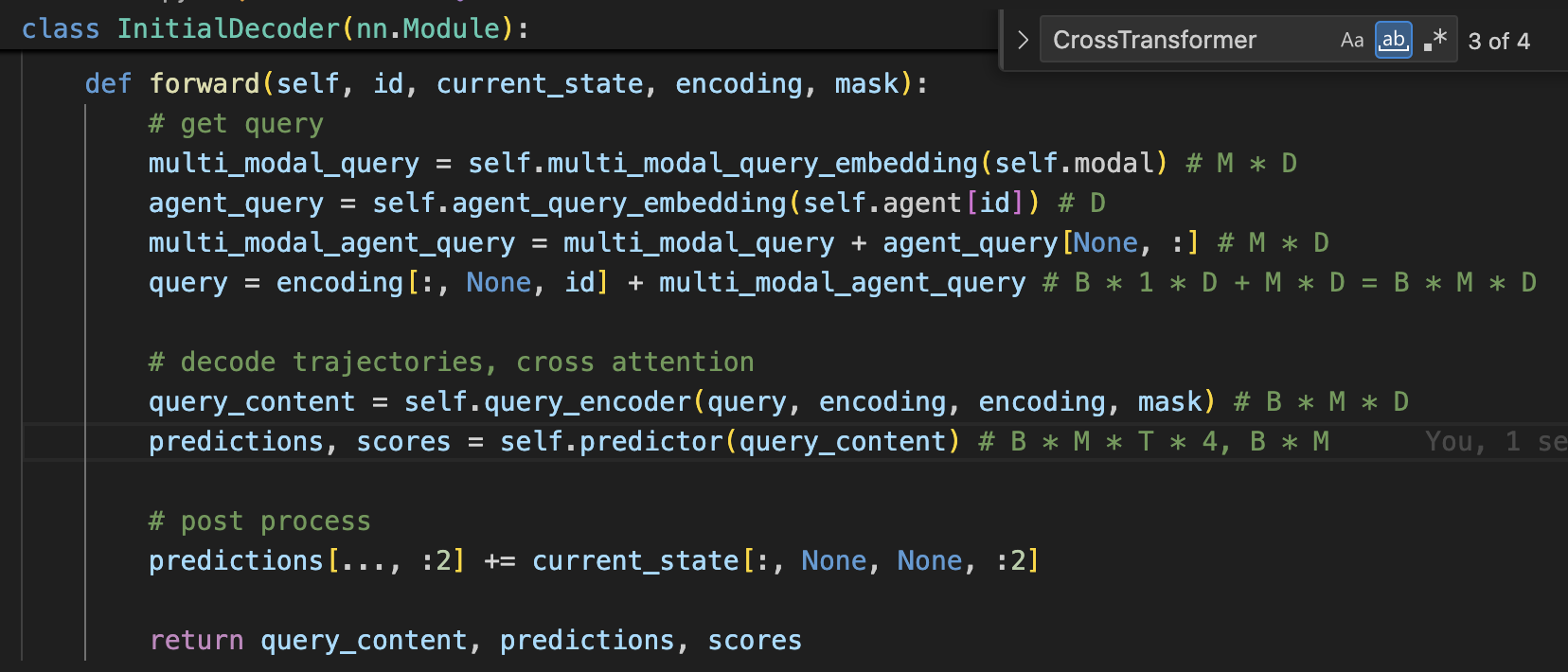
- 这里输入的encoding是id对应的agent的周围环境信息 \(\in R^{(N+N_{mr})*D}\)
- multi_modal_query \(\in R^{M*D}\),模态 \(M\)的值为6
- agent_query \(\in R^{D}\)也是取自一个随机初始化的可学习的embedding
- 前面两者相加得到一个多模态的agent query \(\in R^{M*D}\),再和GM.encoder中对每个agent计算的scene_context_encoding \(\in R^{(N+N_{mr})*D}\)中该agent对应的历史状态维度 \(\in R^{N*None*D}\)相加(在模态维度上新增一个维度),得到最终的query \(\in R^{M*D}\)
- 将scene_context_encoding \(\in R^{(N+N_{mr})*D}\)作为key和value,与上面的query在模态维度上进行cross attention,得到query content \(\in R^{M * D}\),表征该agent的不同预测模态和周围环境的交互编码
- self.predictor即GMMPredictor类,本质上是2个MLP,一个回归GMM参数 \(\in R^{B*M*T*4}\),一个回归score \(\in R^{B*M}\)
-
-
Interaction Decoding
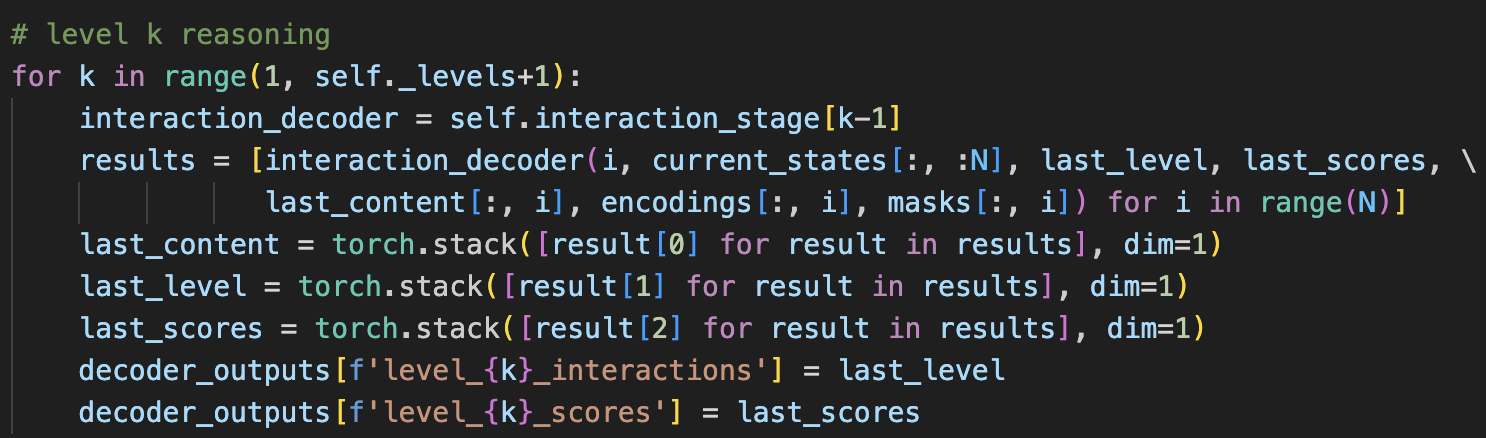
-
核心是interaction_decoder函数( \(k\)个相互独立的InteractionDecoder),它不断拿上一层计算出来的其他agent的predict和score去更新当前关注的agent的未来轨迹(先猜别人怎么走,再思考自己怎么应对)

- future encoding是编码其他agent在上一层( \(k-1\)层)计算的prediction和score, \(\in R^{N*D}\)

- 通过self attention计算上一层的预测之间的关联,并将结果不断concat到对应agent的scene context encoding当中(所以每个agent的scene context encoding包含了最开始的环境中每个障碍物的历史信息,地图信息,以及后面1~ \(k-1\)层的future interaction信息)
- 注意,这里有个mask,是为了让每个agent不看自己在前1~ \(k-1\)层的future encoding。

- 这里把当前关注agent在 \(k-1\)层的query content和该agent的预测轨迹编码相加作为query,该agent的scene context encoding作为key和value,通过multi-head cross-attention Transformer得到该agent在本层的query content
- 最后通过一个GMMPredictor回归最新的GMM prediction和scores
- future encoding是编码其他agent在上一层( \(k-1\)层)计算的prediction和score, \(\in R^{N*D}\)
-
-
- GF网络主体,encoder + decoder