CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving
摘要
- 本文提出CarPlanner——一种基于强化学习生成多模态轨迹的一致性自回归规划器。
- 其自回归结构支持高效的大规模强化学习训练,而引入的一致性机制通过保持跨时间步长的时序一致性,确保了策略学习的稳定性。此外,CarPlanner采用生成-选择框架,结合专家引导的奖励函数与不变视角模块,既简化了强化学习训练流程,又提升了策略性能。
- 有效解决了训练效率与性能提升的双重挑战。
- 首次证明了基于强化学习的规划器能够在具有挑战性的大规模真实世界数据集nuPlan上超越基于模仿学习(IL)和基于规则的最先进方法(SOTA)
相关工作
- IL存在分布偏移与因果混淆问题
- RL存在1)训练效率低下 2)性能表现不足的问题
- 当前生成多步轨迹的方法主要分为两类:“初始化-优化”模型与“自回归模型”
- 方法A通过生成初始轨迹估计,并利用迭代式强化学习进行优化。然而,最新研究(如Gen-Drive)表明,该方法仍落后于基于模仿学习与规则的最优规划器。该框架的显著缺陷在于忽视了轨迹规划任务内在的时序因果性。此外,直接在高维轨迹空间进行优化所引发的复杂性,会制约强化学习算法的性能表现。
- 方法B采用自回归模型,通过在状态转移模型内运用单步策略循环生成自车位姿序列形成完整规划轨迹。由于考量了时序因果关系,现有自回归模型能够生成交互式驾驶行为。但此类方法的共性局限在于依赖从动作分布中自回归随机采样来生成多模态轨迹,这种基础自回归流程可能损害长期一致性并过度扩展强化学习的探索空间,最终导致性能下降。
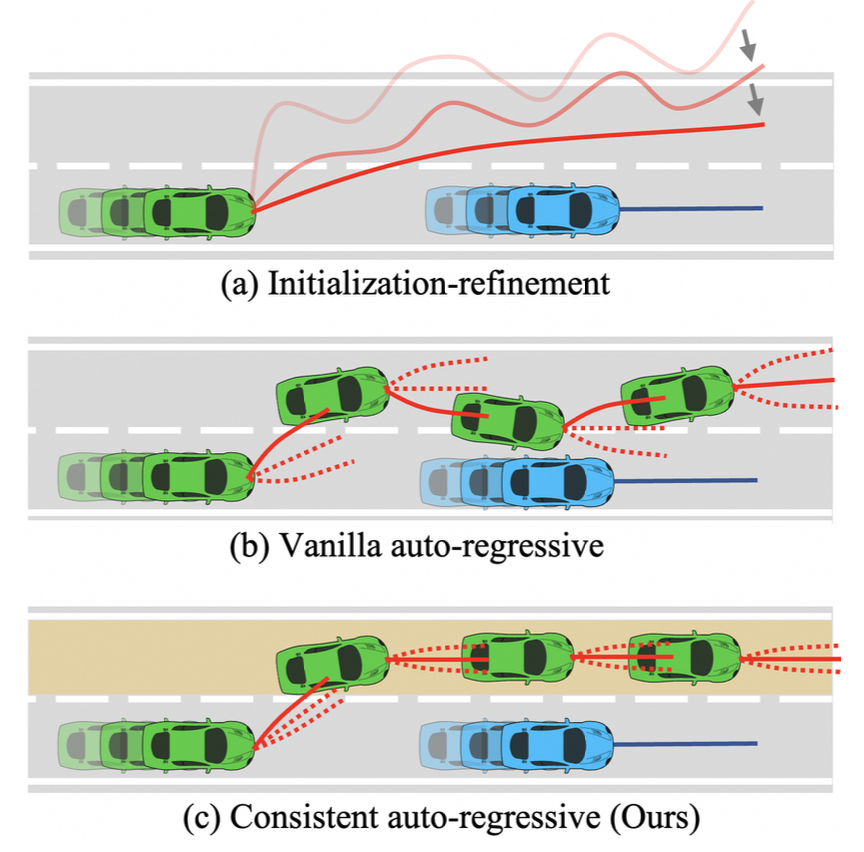
- 针对自回归模型的固有缺陷,将一致性模式表征作为自回归的条件约束。
- 采用纵向-横向分解模式表示法:纵向模式通过标量参数捕获平均速度特征,横向模式则基于自车当前状态与地图信息生成所有可行路径集合。此类模式在轨迹生成的时间维度上保持恒定,为策略采样过程提供稳定一致的行为引导。
- 设计了适用于大规模多样化场景的通用奖励函数。
- 专家引导项:通过量化规划轨迹与专家轨迹的位移误差(结合一致性模式表征),有效缩小策略探索空间。
- 任务导向项:集成碰撞规避、可行驶区域约束等驾驶常识性指标。
- 此外,我们引入不变视角模块(Invariant-View Module, IVM),通过将智能体状态与横向模式信息转换至自车当前坐标系,并裁剪远端无关信息,为策略网络提供与时间无关的标准化输入,从而简化特征学习过程并增强泛化能力。
方案
强化学习基本范式
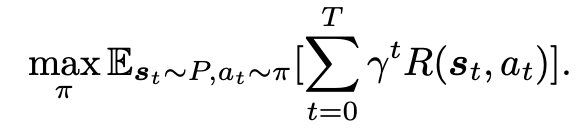
- \(S\):状态空间
- \(A\):动作空间
- \(P\):状态转移概率
- \(R\):奖励函数
- \(T\):规划时长
- \(\gamma\):奖励衰减系数
- \(\pi\):动作采样策略
- \(a_{t}\): \(t\)时刻采样的动作
- \(s_{t}\): \(t\)时刻状态
- \(\tau\):状态-动作序列(轨迹)
- 目标是最大化奖励
向量化的状态表征
- \(s_{t}\)
- map
- 道路拓扑、 交通信号灯(通过polylines和polygons表示)
- agent
- 历史状态
- map
问题建模
- 将自回归模型解耦为policy model 和 transition model(本质上就是周围其他agent的轨迹预测模型)
- 将动作定义为下一个时刻的状态 \(a_{t} = s_{t+1}^{0}\)

- 从上面公式可以看到典型自回归方法相关的固有问题:动作来源于从策略分布中随机采样,进而导致前后帧的不一致行为。为了解决该问题,引入前后帧一致的模式信息 \(c\)

- 上面的公式展示了一个“生成-选择”架构的运行逻辑。模式选择器根据初始状态 \(s_{0}\)对候选模式进行打分,轨迹生成器根据模式的指导生成多模态轨迹
规划器架构
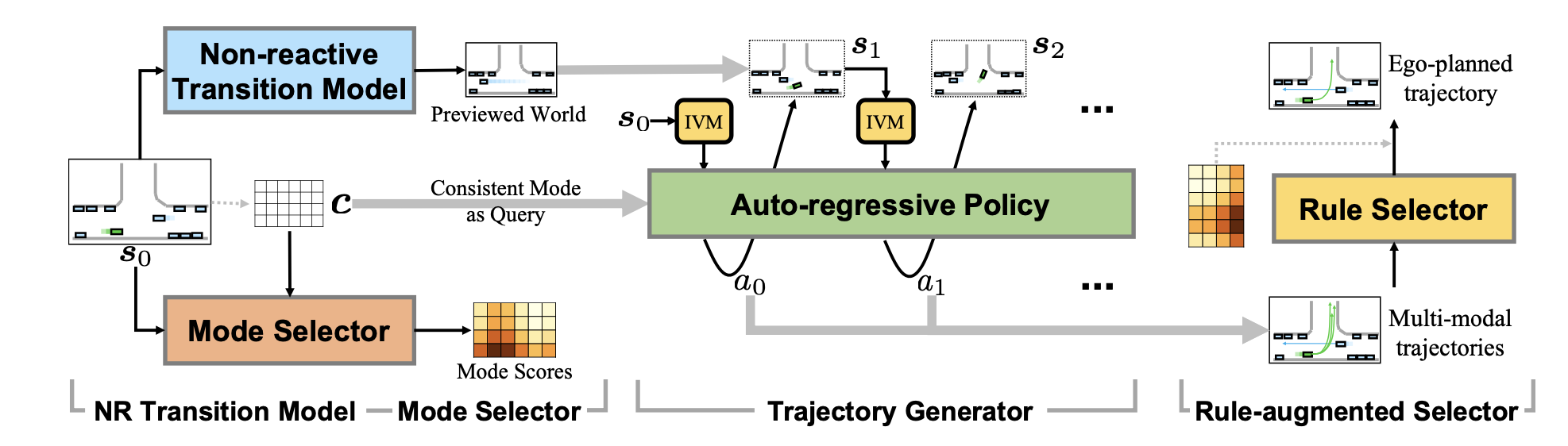
- 四个部分组成
- 非交互的状态转移模型
- 模式选择器
- 轨迹生成器
- 规则增强选择器
Map编码
- 每个lane通过polyline表示,包含 \(3N_{p}\)个点,中心点、左边界点、右边界点;每个点特征 \(D_{m}=9\)(x, y, heading, speed limit, category)。
- intersections, crosswalks, stop lines通过polygon表示
- 通过PointNet提取特征后concat在一起得到 \(N_{m}*D\)
Agent 编码
- 每个障碍物保留过去 \(H\)帧的状态,每个状态特征 \(D_{a}=10\)(x, y, heading, vel, bbox, timestamp, category)。
- 通过PointNet提取特征后concat在一起得到 \(N_{a}*D\)
非交互式的状态转移模型
- 状态转移模型负责给环境中所有agent生成下一个时刻的状态(就是每个time step给所有agent做一次推演)。这个过程比较耗时,并且相比直接拿历史信息一次性生成整段预测轨迹的无交互预测模型并没有引入性能上的优化,所以实际实现的时候这边直接用了一个预测模型给除自车外的agent一次性生成整段多模轨迹。(本质是一个decoder从BEV feature中生成障碍物预测轨迹)
- TODO:ego和obs的交互自洽如何满足?
模式选择器
- 该模块以初始状态s₀及纵向-横向分解模式信息为输入,输出各模式的概率分布。
路径-速度解耦模式表征
- 为捕捉纵向行为特征,我们生成 \(N_{lon}\)个表征轨迹平均速度的模式。每个纵向模式 \(c_{lon,j}\)定义为标量值 \(\frac{j}{N_{lon}}\),沿维度 \(D\)重复扩展,形成维度为纵向 \(N_{lon}\times D\)模式的矩阵。针对横向行为,我们通过图搜索算法从地图中提取 \(N_{lat}\)条可行路径,对应自车可用车道。原始路径表征维度为 \(N_{lat}\times N_{r} \times D_{m}\)( \(N_{r}\)为路径点数, \(D_{m}\)为特征维度)。采用PointNet点云网络聚合路径点特征,生成维度 \(N_{lat}\times D\)的横向模式。将纵向与横向模式拼接后形成维度 \(N_{lat}\times N_{lon} \times 2D\)的复合模式表征 \(c\),经线性层映射至 \(N_{lat}\times N_{lon} \times D\)以对齐特征空间,最终模式总数 \(N_{mode}=N_{lat}N_{lon}\)。
基于查询的Transformer解码器
- 该解码器融合模式特征与 \(s_{0}\)中包含的地图/智能体特征。工作机制如下:以模式特征作为query,地图与智能体信息作为key-value。更新后的模式特征经MLP解码得到各模式评分,最终通过softmax归一化。
轨迹生成器
- 该模块以自回归方式运行,基于当前状态 \(s_{t}\)与恒定模式信息 \(c\),循环解码自车下一时刻位姿 \(a_{t}\)。
不变视角模块(IVM)
- 每个time step对下个时刻的自车位姿进行估计之前都要执行该操作:对模式与状态输入网络前进行预处理以消除时间信息
- 近邻筛选:对状态 \(s_{t}\)中的地图与智能体信息,选择距离自车当前位姿最近的K近邻(KNN)作为输入(K分别取地图/智能体元素总数的50%)
- 路径裁剪:针对表征横向行为的路线,以距离自车当前位置最近的路径点为起点,保留 \(K_{r}\)个点( \(K_{r}\)=单条路线 \(N_{r}\)点数的25%)
- 坐标系对齐:将路线、智能体及地图位姿转换至ego当前时刻 \(t\)的坐标系下
- 时序标准化:将历史时间步 \(t-H:t\)转换为相对当前时刻 \(t\)的 \([-H:0]\)区间
基于查询的Transformer解码器
- 采用与模式选择器相同的主干网络架构,但query维度不一样(因为IVM的作用,同一时刻下不同模态的下自车坐标系内环境信息是不同的,所以无法共享):
- Query: \(1 \times D\)维度(单模式特征)
- Key-Value: \((N+Nₘ)\times D\)维度( \(N\)智能体+ \(N_{m}\)地图要素)
- 输出特征: \(1 \times D\)维度(保持与查询维度一致)
策略输出层
- 模式特征通过两个不同的head进行处理(A2C方法):
- policy head(Actor网络):通过MLP生成动作分布参数(高斯分布)
- 训练阶段:从分布中采样动作以促进探索
- 推理阶段:直接采用分布均值作为确定性输出
- value head(Critic网络):通过独立MLP估计状态价值
- 数学建模:动作分布建模为 \(\mu + \sigma\)的高斯形式,策略优化基于PPO等强化学习算法实现。
- policy head(Actor网络):通过MLP生成动作分布参数(高斯分布)
规则后处理
- 多模态输入:接收初始状态 \(s_{0}\)、自车多模态规划轨迹集、周边智能体预测轨迹
- 规则化评估:基于预设规则计算
- 安全性:轨迹与障碍物的最小距离
- 行进效率:轨迹终点纵向位移
- 舒适度:加速度/加加速度的L2范数
- 综合评分:将规则得分与模式选择器的模式评分加权求和
- 最优选择:选取综合评分最高的轨迹作为规划器最终输出
训练
- 采用分阶段训练架构,核心流程如下:
- 状态转移模型预训练
- 优先训练非交互式的状态转移模型(预测任务预训练)
- 训练模式选择器与轨迹生成器时冻结状态转移模型参数
- 模式选择&轨迹生成
-
不输入所有模式给到轨迹生成模型,只输入正样本模式
-
正样本模式确定方法:
横向模式:根据真实轨迹终点所在路径段确定
纵向模式:将轨迹起点至终点的纵向距离等分为 \(N_{lon}\)区间,匹配对应模式
-
- 损失函数设计
-
模式选择损失:
▫ 正样本模式交叉熵损失(负对数似然)
▫ 辅助任务:真实轨迹回归损失
-
轨迹生成损失:PPO算法三要素
▫ 策略改进项(Policy Improvement)
▫ 价值估计项(Value Estimation)
▫ 熵正则项(Entropy Regularization)
-
- 奖励函数构建
-
基础奖励:自车未来位姿与真实轨迹的负位移误差(DE)
-
增强约束:
▫ 碰撞检测:发生碰撞时奖励-1
▫ 可行驶区域合规性:越界时奖励-1
▫ 正常行驶时奖励保持0
-
- 模式丢失正则化
- 动机:防止Transformer结构中的残差连接导致对mode或route过于依赖
- 实现:训练时随机屏蔽部分路径信息(mask概率=20%)
- 效果:增强模型对局部信息缺失的鲁棒性
实验
仿真平台
- 采用nuPlan仿真器
-
交通参与者行为模式:
▫ 非反应模式:日志回放(log-replay)
▫ 反应模式:IDM策略(智能驾驶员模型)
-
自车控制架构:用户规划器生成轨迹 → LQR控制器跟踪生成控制指令
-
仿真参数:15秒时长/10Hz更新频率
-
基准测试集与评估指标
- 采用两大基准测试集:
- Test14-Random(来自PlanTF):261个场景
- Reduced-Val14(来自PDM):318个场景
- 评估采用nuPlan官方闭环综合评分(CLS),包含:
- 安全指标:碰撞率(S-CR)、碰撞时间(S-TTC)
- 可行驶区域合规性(S-Area)
- 行进效率(S-PR)
- 舒适度指标
实验细节
- 数据划分(遵循PDM标准):
- 训练集:176,218个场景(14类×4,000场景)
- 验证集:1,118个场景(14类×100场景)
- 训练配置:
- 硬件:2×NVIDIA 3090 GPU
- 训练轮次:50 epochs
- 批量大小:64/GPU
- 优化器:AdamW(初始学习率1×10⁻⁴,验证损失停滞时学习率衰减因子0.3)
- 强化学习参数:
- 折扣因子γ=0.1
- GAE参数λ=0.9
- 损失权重:价值损失3,策略损失100,熵损失0.001
- 模式参数:
- 纵向模式数:12
- 最大横向模式数:5
SOTA对比
方法分类与对比基准
- 基于轨迹生成器类型,我们将现有方法划分为规则驱动(Rule)、模仿学习(IL)与强化学习(RL)三大类:
- PDM:2023年nuPlan挑战赛冠军
- PDM-Closed:IL+规则混合框架,采用IDM生成候选轨迹,基于安全/效率/舒适度的规则选择器优选轨迹
- PDM-Open:纯规则驱动版本
- PLUTO:生成-选择框架,结合对比模仿学习(Contrastive IL)与数据增强技术训练生成器
- GenDrive:预训练-微调流程,先通过IL预训练扩散模型规划器,再基于AI偏好训练的奖励模型进行RL微调去噪过程
- PDM:2023年nuPlan挑战赛冠军
实验结果分析
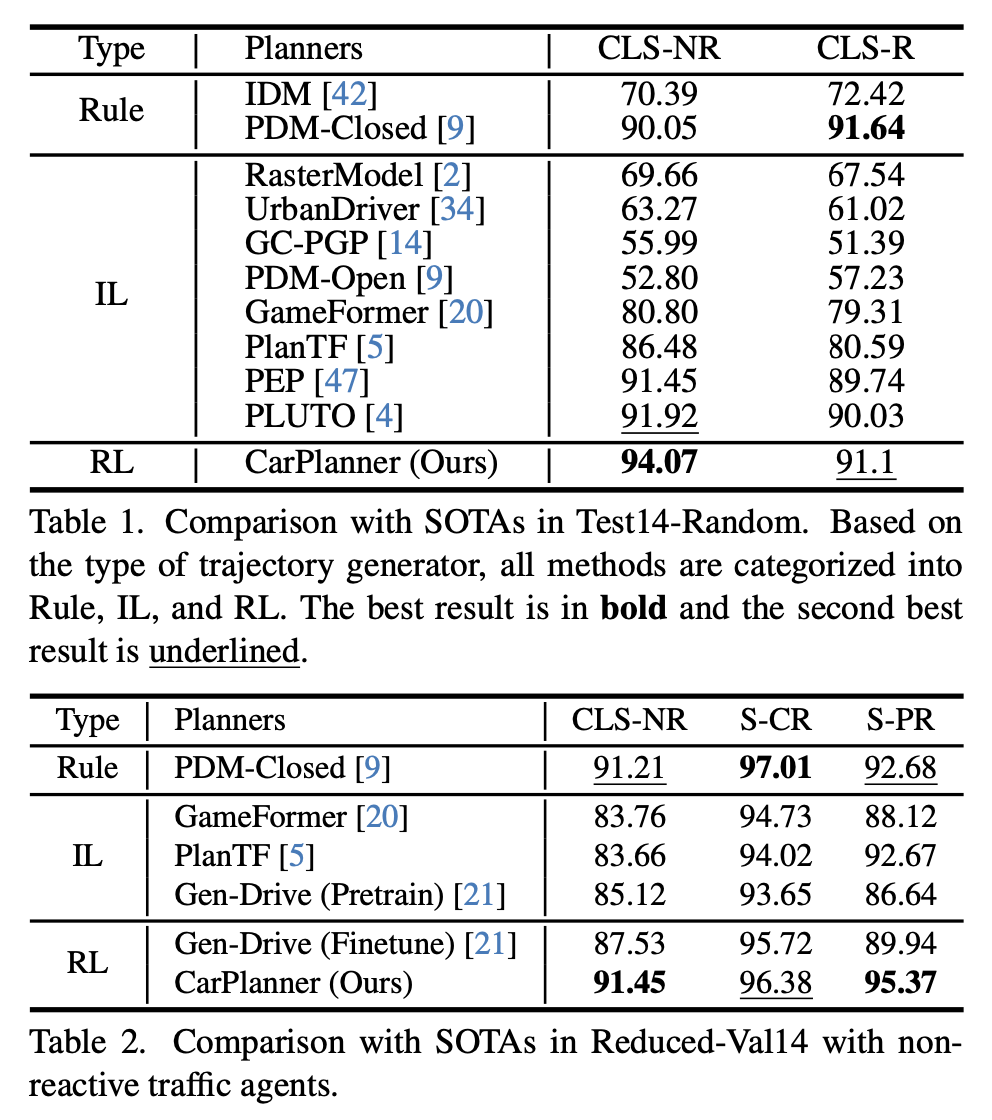
如表1(Test14-Random)与表2(Reduced-Val14)所示,CarPlanner在无交互场景(障碍物不对自车行为作出反应)中展现显著优势:
-
无交互式场景(CLS-NR):
▫ 全指标领先,较PDM-Closed与PLUTO分别提升4.02与2.15分
▫ 行进效率(S-PR)显著优于PDM-Closed(表2对比)
▫ 碰撞率(S-CR)与基准方法持平,验证安全驾驶保障能力
技术亮点:未使用数据增强、驾驶历史掩码等IL常用技术,彰显闭环任务解决能力
-
交互式场景(CLS-R):
▫ 性能略逊于PDM-Closed
原因分析:模型仅在无交互式场景训练,未接触IDM策略驱动的动态交互环境,导致对反应式智能体扰动鲁棒性不足
总结
- RL方法潜力验证:在无交互式场景全面超越IL与规则方法
- 效率-安全平衡:在保持碰撞率水平的同时显著提升行进效率
- 场景泛化局限:反应式场景性能揭示跨模式训练必要性
消融实验
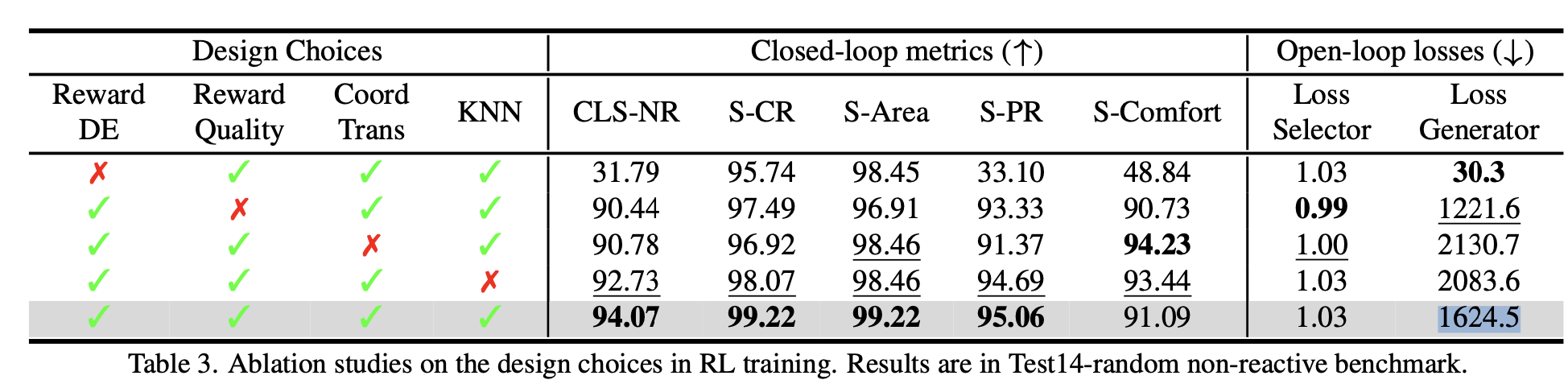
奖励项作用
- 只生效质量奖励(Quality Only: collision check + drivable area check):
- 规划器倾向于生成静态轨迹,行进效率(S-PR)显著降低
- 成因分析:自车初始处于安全可行驶状态,前行将面临碰撞/越界风险,导致策略陷入局部最优
- 质量+位移误差奖励(Quality+DE):
- 碰撞率(S-CR)从97.49→99.22,提升1.73%
- 可行驶区域合规性(S-Area)从96.91→99.22,提升2.31%
IVM模块有效性验证
- 坐标变换技术&KNN近邻筛选对最终表现的优化有较大收益
与IL的对比
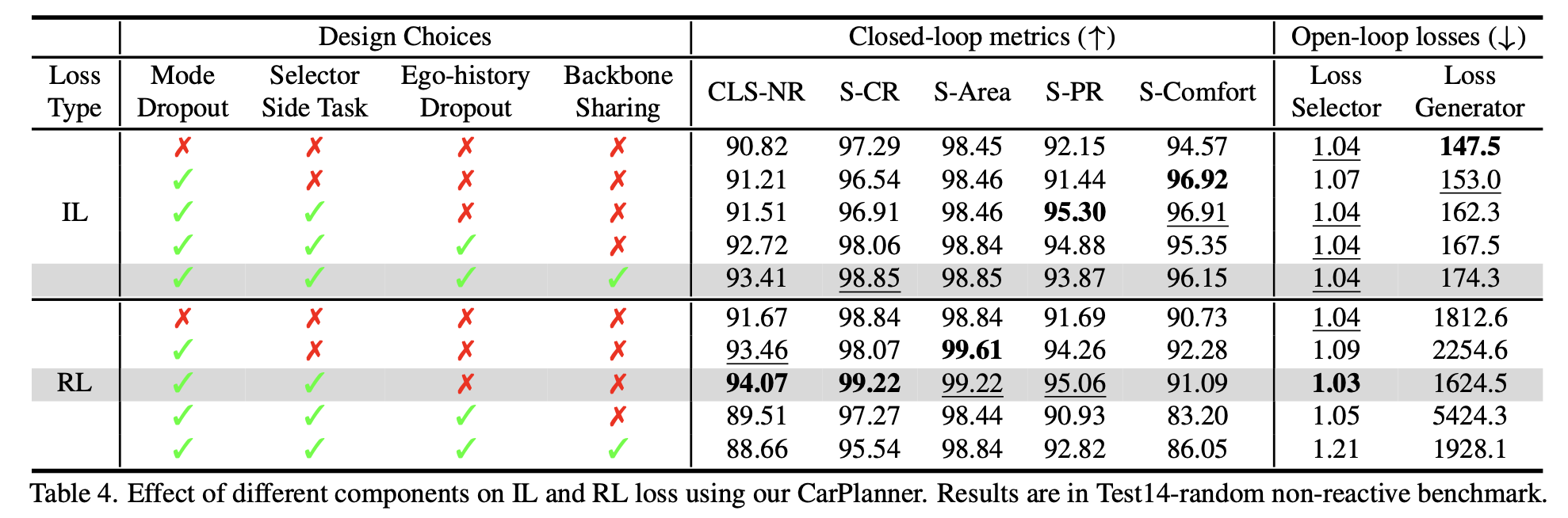
- mode dropout和selector side task对IL和RL训练都有较大的帮助
- ego-history dropout
- 对IL帮助较大,提升碰撞率(S-CR)与可行驶区域合规性(S-Area),
- 随机屏蔽历史位姿与当前速度,缓解因果混淆问题
- 对RL则不是很重要
- 较大程度影响生成器loss中的value评估部分,闭环性能下降
- 原因:RL通过奖励信号自动挖掘因果关系,无需人工干预
- 对IL帮助较大,提升碰撞率(S-CR)与可行驶区域合规性(S-Area),
- backbone sharing
- 常用于IL场景,通过特征共享,提升泛化能力
- 在RL场景起到反作用,引发不同任务之间的梯度冲突,轨迹生成器和模式选择器损失上升
- TODO:轨迹生成那边是循环生成下一帧轨迹的,前后帧感觉无法共享特征?
场景化定性分析
-
自车右转避让行人的复杂场景
-
规则方法

- 未能预判行人动态,采取紧急制动仍与行人轨迹交叠
-
IL方法

- 感知到行人运动趋势,及时启动制动操作,但与行人保持纵向距离不足(<0.5m)
-
RL方法

- 提前横向避让,构建横向安全缓冲区(1.2m),行进效率与安全指标均达最优